Kodeclik Blog
Everything you need to know about Python hash()
Python’s hash() function is used to generate a unique "hash" value (typically an integer) that can be used to identify a particular object or data structure rapidly. Hashes are used wherever you need fast retrieval and lookup operations, e.g., think of a search engine that has to return webpages in milliseconds.
To understand how hashes work, let us dive right in! Consider the following code:
name = "Kodeclik Online Academy"
camp = "Kodeclik Online Academy"
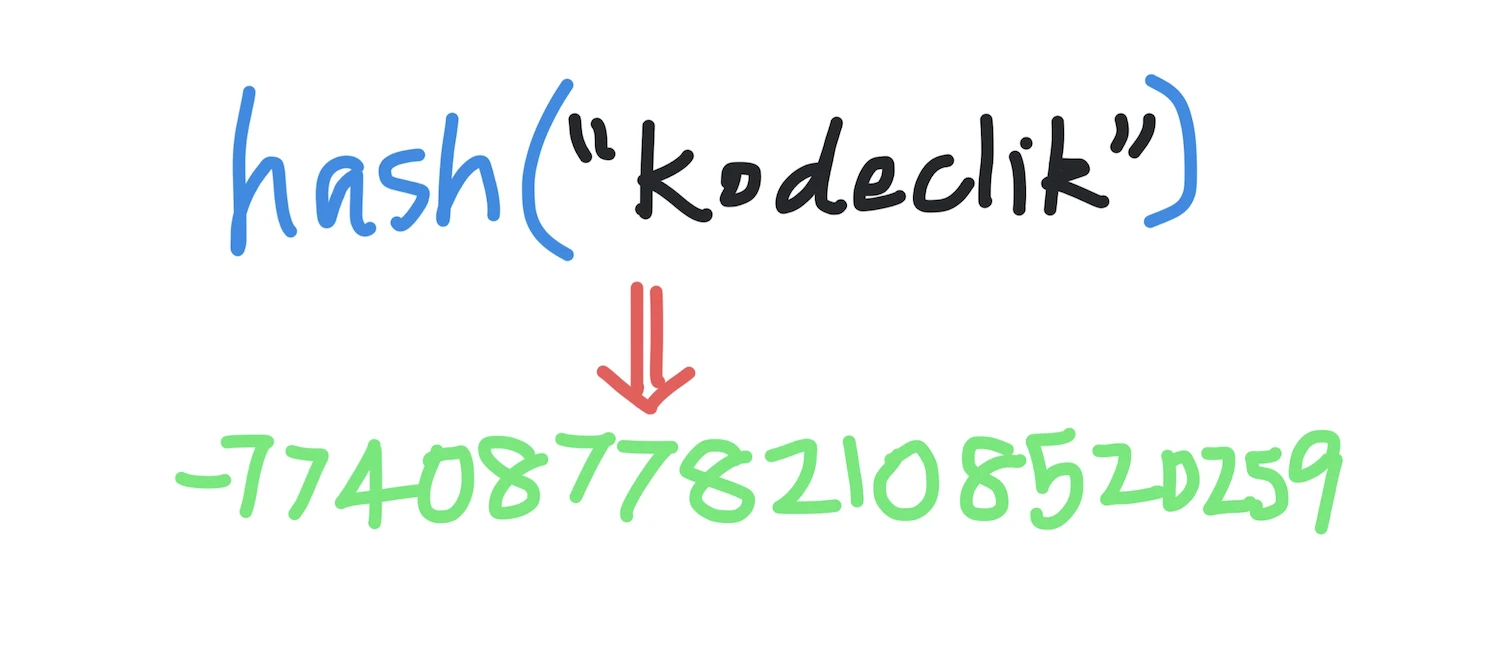
us = "Kodeclik"
print(hash(name))
print(hash(camp))
print(hash(us))Here we have defined three string variables, namely “name”, “camp”, and “us”. Two of the variables are initialized to the same string value (“Kodeclik Online Academy”) and the third to a different string value (i.e., “Kodeclik”). We then use the hash function to compute the hash of each and print it.
The output is (your output might vary):
-2497879565738511318
-2497879565738511318
-774087782108520259Note that hashing essentially creates a unique identifier (number) for any given piece of data (in our case, the data items are strings). A hash value doesn't necessarily need to make sense; it just needs to be unique so that it can be used as an identifier. Thus, we can see that the hash for variables “name” and “camp” are really the same. But the hash for variable “us” is different, as it should be.
Hashing is incredibly useful because it allows us to easily store and retrieve information without needing to look through every element of a data structure every time we want something specific. For example, say you had a list of names (imagine millions) and wanted to quickly find one by name without having to search through all of them one at a time—you could use the hash() function on each name in the list and then store the resulting hashes in a dictionary with the associated names as keys. Then when you want to lookup a record, you can lookup by the corresponding hash value.
Theoretically, hashing should create a unique number for each input, but in practice there are times when two different inputs produce the same result—this is known as a "collision." When this happens, the programmer may have to find another method to uniquely identify their objects or data structures. But this happens quite rarely so you should confidently use hashes for a lot of practical purposes.
Note that there is no way to “reverse-engineer” what the original input was that gave rise to a given hash value. That is because this is not needed. All we care about is to hash a given object and then see if the hashes match.
Python's built-in hash() function takes any immutable object—strings, tuples, integers, floats—and returns an integer representing that object. It does this by taking the object's contents and using an algorithm to produce a unique numerical value (the "hash").
Let us try hash with some other object types:
pi_approx = 3.1415
letter_tuple = ("A", 1, 65)
seasons_list = ['Summer', 'Fall', 'Winter', 'Spring']
print(hash(pi_approx))
print(hash(letter_tuple))
print(hash(seasons_list))Here we have a floating point number, a tuple (of three elements) and a list. We compute the hashes for each and print them. The output is (again your specific hash values might be different):
326276785803738115
8414570937767118818
Traceback (most recent call last):
File "main.py", line 6, in <module>
print(hash(seasons_list))
TypeError: unhashable type: 'list'Note that the first two hash functions work and return large integers. (This time they are positive values but again this is not something you can predict deterministically). But the hash for the list fails. Why? This is because lists are mutable types, i.e., a list can be modified, added to, or deleted from, after assignment. Thus the hash function does not work on lists.
Creating hashes for custom Python classes
Let us suppose we create a class called “Book” to denote books and their names, authors, year of publication, and publisher.
class Book:
def __init__(self, name, author, year, publisher):
self.name = name
self.author = author
self.year = year
self.publisher = publisher
HarryPotter1 = Book("Harry Potter and the Philosopher's Stone",
"J.K. Rowling", 1997, "Bloomsbury")Here, following the class definition we have created an object called HarryPotter1. Python knows how to hash these objects as well! So if we try:
class Book:
def __init__(self, name, author, year, publisher):
self.name = name
self.author = author
self.year = year
self.publisher = publisher
HarryPotter1 = Book("Harry Potter and the Philosopher's Stone",
"J.K. Rowling", 1997, "Bloomsbury")
HarryPotter1_copy = Book("Harry Potter and the Philosopher's Stone",
"J.K. Rowling", 1997, "Bloomsbury")
print(hash(HarryPotter1))
print(hash(HarryPotter1_copy))we will obtain:
8736485060596
8736485060590Note that the hashes are slightly different. This means that the usual way by which Python is hashing your custom-defined class is not quite useful in comparing objects. What you can do instead is to custom provide your own __eq__ (for equality checking) and __hash__ functions, like so:
class Book:
def __init__(self, name, author, year, publisher):
self.name = name
self.author = author
self.year = year
self.publisher = publisher
def __eq__(self, x):
return ((self.name == x.name) and
(self.author == x.author) and
(self.year == x.year) and
(self.publisher == x.publisher))
def __hash__(self):
return hash((self.name, self.author,
self.year, self.publisher))
HarryPotter1 = Book("Harry Potter and the Philosopher's Stone",
"J.K. Rowling", 1997, "Bloomsbury")
HarryPotter1_copy = Book("Harry Potter and the Philosopher's Stone",
"J.K. Rowling", 1997, "Bloomsbury")
print(hash(HarryPotter1))
print(hash(HarryPotter1_copy))Here we have defined equality to mean that all the four components of the Book should be the same. The hash function is defined to be just a hash of a tuple containing these four components. When we run this program we obtain:
4086432149305751655
4086432149305751655Note that the hash values are now the same and thus a useful way to index and compare the Book objects.
In summary, Python’s powerful yet simple built-in hash() function provides programmers with an efficient way to map immutable objects to arbitrary numbers and store data with ease - making it ideal for lookup tables or finding duplicate elements in lists or sets quickly and accurately.
The most common use of Python's hash() function is as part of a lookup table; when you need to quickly retrieve data from a large number of records without having to search through them all one by one. Hashing can also be used as part of an algorithm for detecting duplicate elements in a list or set. Additionally, it can be used to check whether two objects are equal; if two objects have the same hash value then they are considered equal regardless of their actual contents. Finally, hashing functions such as SHA-256 can be used for encryption tasks like generating passwords or verifying digital signatures.
By understanding how Python’s hash function works and what uses it has, you will be better equipped to leverage its power whenever needed!
If you liked learning about Python hash(), checkout our blogpost on Python tuple comprehension, an approach to rapidly construct tuples.
Interested in more things Python? Checkout our post on Python queues. Also see our blogpost on Python's enumerate() capability. Also if you like Python+math content, see our blogpost on Magic Squares. Finally, master the Python print function!
Want to learn Python with us? Sign up for 1:1 or small group classes.
